Analysis of TripAdvisor Reviews
All files used for this project can be accessed through this GitHub link.
This analysis was done in R and conducted as part of a work experience with Destination Harrogate, which aims to promote Harrogate as a destination for visitors. I was brought in to uncover insights that could help with planning future activities to draw more visitors into the region.
In total, I analysed the TripAdvisor reviews for 15 attractions around Harrogate. I will use Knaresborough Castle as an example here to illustrate my workflow.
Rationale
This is the key question I was tasked to address: What do people think of Harrogate?
The organisation wanted to get an insight into people’s perceptions so that they can better understand what they’ve done well to attract people to Harrogate, and what steps they need to take next to increase the number of visitors .
Looking at literature in the field of tourism research, one of the most common methods to measure the perception of a tourist destination is through mail-in questionnaires. But given the level of resources I had access to, primary data collection was not going to be an option and neither was third-party paywalled data.
So I turned to data readily available online - particularly social media, which looked to be appropriate as data collection can be free and it holds vast amounts of data about people’s thoughts on virtually anything. One platform stood out - TripAdvisor.
It most directly addresses people’s perceptions of Harrogate as a tourist destination, while other platforms like Facebook or Twitter would contain data about Harrogate’s general reputation or perception of it as a place to live in. Though these data points would still be useful and are undeniably linked to Harrogate’s performance as a tourist destination, it would complicate the analysis considerably while being less actionable for the organisation.
Admittedly, there are some limitations with using TripAdvisor reviews as a data source:
- Only shows perceptions of specific attractions rather than the towns or Harrogate as a whole (though this could also be an advantage as the analysis would be more targeted and actionable)
- Doesn’t take into account the perceptions of residents and those who have yet to visit
- As with any review site, opinions on the platform will be more polarised (many extreme views and few moderate views) than actual perception
Setting Up
The methodology used for this analysis was adapted from a dissertation by Mário Monteiro Andrade Filho.
As there aren’t any free TripAdvisor APIs or webscrapers available, I’ll be conducting the web scraping through R. With these reviews, I will conduct a brief sentiment analysis to get a general understanding of the overall perception. I will then identify the most frequently occurring positive and negative monograms (single words) and bigrams (two-word phrases) to better understand what exactly visitors liked or didn’t like about the attraction to lay out some actionable steps. These will be visualised using word clouds for ease of interpretation.
Before starting, I’ll load in all the libraries I need.
library(rvest) #for web scraping
library(RSelenium) #for web scraping
library(netstat) #to retrieve ports not currently in use
library(tidyverse) #for data cleaning and processing
library(tm) #to clean text data
library(syuzhet) #to extract sentiment from text
library(sentimentr) #for sentiment analysis
library(quanteda) #for tokenisation
library(quanteda.textstats)
library(tidytext) #for bing lexicon
library(wordcloud2) #to create word clouds
library(htmlwidgets) #to export the word clouds
library(webshot) #to export as .png
library(pander) #to create tablesWeb Scraping
While rvest is typically much quicker at web scraping, it unfortunately doesn’t work on TripAdvisor on my system so I’ve opted to use RSelenium instead.
I’ll scrape the first page of reviews for Knaresborough Castle before moving onto the remaining pages.
url <- "https://www.tripadvisor.co.uk/Attraction_Review-g504004-d2262911-Reviews-Knaresborough_Castle-Knaresborough_North_Yorkshire_England.html"
#Open TripAdvisor URL using Selenium
rD <- rsDriver(browser = "chrome", port = free_port(), chromever="108.0.5359.71", check = F, verbose = F)
remDr <- rD[["client"]]
remDr$navigate(url)
#reading html using selenium and storing it
html <- remDr$getPageSource()[[1]]
#using rvest to extract html info
html <- read_html(html)With the html data now in my environment, I’ll extract the reviews by identifying the corresponding html nodes. I used the SelectorGadget extension on Google Chrome to help identify the right nodes.
#extracting reviews
reviews <- html%>%
html_nodes('.yCeTE') %>%
html_text()I will close off any RSelenium processes before proceeding further to make sure it doesn’t interfere with the scraping of subsequent pages and to free up memory space.
#closing off any programs
Sys.sleep(2)
remDr$closeall()
rD[["server"]]$stop()
system("taskkill /im java.exe /f", intern=FALSE, ignore.stdout=FALSE)As TripAdvisor’s URLs follow a set structure, I can create a loop to automate the web scraping for all pages of reviews. Looking at the URLs, the highlighted portions show how the URL differs from one page to another.
| Reviews | URL |
|---|---|
| 1-10 | tripadvisor.co.uk/Attraction_Review-g504004-d2262911-Reviews-Knaresborough_Castle-Knaresborough_North_Yorkshire_England.html |
| 11-20 | tripadvisor.co.uk/Attraction_Review-g504004-d2262911-Reviews-or10-Knaresborough_Castle-Knaresborough_North_Yorkshire_England.html |
| 21-30 | tripadvisor.co.uk/Attraction_Review-g504004-d2262911-Reviews-or20-Knaresborough_Castle-Knaresborough_North_Yorkshire_England.html |
Since they go up in increments of 10, I can extract the number of reviews from the page and create a sequence of numbers based on the total review count.
#extracting number of reviews
review_count <- html %>% html_nodes('.Ci') %>% html_text()
review_count## [1] "Showing results 1-10 of 1,289"#Extracting the number from the string
review_count <- strsplit(review_count,'of ')[[1]][2]
review_count## [1] "1,289"#removing commas in the number and storing it as numeric object
review_count <- as.numeric(gsub(',','',review_count))
review_count## [1] 1289#Creating sequence for tripadvisor URLs
num <- seq(10, review_count, 10)I can then use this sequence of numbers to automate the web scraping using a for loop.
#automating web scraping for all reviews
for (i in 1:length(num)) {
#generating url
revurl <- paste0("https://www.tripadvisor.co.uk/Attraction_Review-g504004-d2262911-Reviews-or",num[i],"-Knaresborough_Castle-Knaresborough_North_Yorkshire_England.html")
#opening browser through Selenium
rD <- rsDriver(browser = "chrome", port = free_port(), chromever="108.0.5359.71", check = F, verbose = F)
remDr <- rD[["client"]]
remDr$navigate(revurl)
#reading in the webpage
html <- remDr$getPageSource()[[1]]
html <- read_html(html)
#extracting reviews
reviewed <- html%>%
html_nodes('.yCeTE') %>%
html_text()
#adding our scraped reviews to existing reviews
reviews <- c(reviews,reviewed)
#closing browser
Sys.sleep(2)
remDr$closeall()
rD[["server"]]$stop()
}
system("taskkill /im java.exe /f", intern=FALSE, ignore.stdout=FALSE)
#Saving reviews to our folder to make sure we don't have to conduct the web scraping again in case R crashes.
save(reviews, "reviews.RData")Data Cleaning
Now that we have the data for all reviews in our environment, let’s inspect what we’re working with.
head(reviews, n = 6)## [1] "Fine views of the river and viaduct"
## [2] "Easy to find if you park in one of the main town centre car parks. Free to walk around and some of the finest views you'll find in the UK. Museum and castle keep entry combined is £3.50 which was very reasonable. My only issue is the potentially unlawful and discriminatory practice operated by Harrogate Council by enforcing card payments only. No cash can be used to pay for entry or to buy anything from the museum gift shop. The keep itself wasn't much to explore but for £3.50 and the museum included it was worth it."
## [3] "Lovely remains of such a historic site"
## [4] "We enjoyed walking around the castle and surrounding gardens with their amazing history and beautiful views. We loved this twon and definitely hope to return soon."
## [5] "For the best views of the viaduct!"
## [6] "Wonderful free to enter attraction, very well maintained gardens and breath taking views of the viaduct, not to be missed!"Comparing this with the reviews online, it appears that the title and body of each review have been recorded as separate entries. I’ll also check if the number of entries I have is exactly double that of the number of reviews on the site to make sure that I didn’t miss any reviews in the scraping process.
length(reviews)## [1] 2578Thankfully, it’s exactly double, so I can be sure that I have scraped every review on the site.
As I conducted this analysis 15 times, there were occasions when the number of reviews didn’t line up and it was usually because the scraping stopped prematurely as I ran out of memory space. I then had to find out where it left off by checking the number of reviews and re-start the loop from there.
Now, I’ll merge the title and body for each entry to form the full review. I’m adding a full stop between the title and body so that the title can be recognised as its own sentence for the sentiment analysis later.
#merging alternate rows to re-form full review
nreviews <- length(reviews)/2
knaresreview <- sapply(1:nreviews, function(x){
paste(reviews[2*x-1], ".", reviews[2*x])})
#inspecting
head(knaresreview, n = 3)## [1] "Fine views of the river and viaduct . Easy to find if you park in one of the main town centre car parks. Free to walk around and some of the finest views you'll find in the UK. Museum and castle keep entry combined is £3.50 which was very reasonable. My only issue is the potentially unlawful and discriminatory practice operated by Harrogate Council by enforcing card payments only. No cash can be used to pay for entry or to buy anything from the museum gift shop. The keep itself wasn't much to explore but for £3.50 and the museum included it was worth it."
## [2] "Lovely remains of such a historic site . We enjoyed walking around the castle and surrounding gardens with their amazing history and beautiful views. We loved this twon and definitely hope to return soon."
## [3] "For the best views of the viaduct! . Wonderful free to enter attraction, very well maintained gardens and breath taking views of the viaduct, not to be missed!"I’ll clean up the data by removing any duplicates and removing all numbers and punctuations within the text aside from full stops.
#removing duplicated entries
knaresreview <- knaresreview[!duplicated(knaresreview)] #removed 1 row of dataThis removed 1 duplicated review, so we have 1288 reviews now.
Next, I’ll clean up the text data. One things to note is that I’m removing stop words before removing punctuations as some of the stop words contain punctuations (e.g. we’ll, we’ve, they’re)
#converting everything into lowercase
knaresreviewclean <- tolower(knaresreview)
#removing digits
knaresreviewclean <- gsub(pattern="\\d", replace=" ", knaresreviewclean)
#removing stop words
knaresreviewclean <- removeWords(knaresreviewclean, stopwords())
#removing punctuations
knaresreviewclean <- gsub(pattern="[[:punct:] ]+", replace=" ", knaresreviewclean)
#removing single letters/orphans
knaresreviewclean <- gsub(pattern="\\b[A-z]\\b{1}", replace=" ", knaresreviewclean)
#removing additional white spaces
knaresreviewclean <- stripWhitespace(knaresreviewclean)
#inspecting cleaned data
head(knaresreviewclean, n = 3)## [1] "fine views river viaduct easy find park one main town centre car parks free walk around finest views find uk museum castle keep entry combined reasonable issue potentially unlawful discriminatory practice operated harrogate council enforcing card payments cash can used pay entry buy anything museum gift shop keep much explore museum included worth "
## [2] "lovely remains historic site enjoyed walking around castle surrounding gardens amazing history beautiful views loved twon definitely hope return soon "
## [3] " best views viaduct wonderful free enter attraction well maintained gardens breath taking views viaduct missed "Identifying Words with Incorrect Polarities
While I would prefer to first conduct sentiment analysis to get a general overview of visitors’ perceptions, I want to identify positive and negative monograms/bigrams before proceeding further to check if there any words or phrases that are inappropriately tagged as positive/negative in this context.
To do this, I’ll tokenise the words and identify the most frequent monograms and bigrams within the reviews.
#tokenising words
tokenised <- tokens(knaresreviewclean, what = 'word', remove_number = T, remove_punct = T, remove_symbols = T)
#identifying monograms and bigrams
token_list <- tokens_ngrams(tokenised, n = 1:2,concatenator = ' ')
token_list <- dfm(token_list)
token_freq <- textstat_frequency(token_list)
bigram_freq <- token_freq[grepl(' ',token_freq$feature),]
monogram_freq <- token_freq[!grepl(' ',token_freq$feature),]
#inspecting data
head(monogram_freq, n = 5)## feature frequency rank docfreq group
## 1 castle 1645 1 949 all
## 2 views 1030 2 749 all
## 3 river 837 3 651 all
## 4 visit 574 4 448 all
## 5 lovely 563 5 433 allhead(bigram_freq, n = 5)## feature frequency rank docfreq group
## 33 worth visit 189 32 179 all
## 35 views river 174 35 168 all
## 36 river nidd 173 36 163 all
## 37 well worth 166 37 159 all
## 41 great views 144 41 132 allNow that I have the full list of monograms and bigrams, I can use sentiment analysis to identify whether these words and phrases are positive, negative, or neutral. I’ve opted to use a lexicon-based sentiment analysis here as it’s the simplest method while remaining fairly appropriate for individual words or phrases.
#Obtaining sentiments of words and phrases
monogram_senti <- get_sentiment(monogram_freq$feature, method = 'bing')
bigram_senti <- get_sentiment(bigram_freq$feature, method = 'bing')
#Creating dataframes for the monograms and bigrams
monograms <- data.frame(monogram_freq, monogram_senti)
bigrams <- data.frame(bigram_freq, bigram_senti)
#Looking at the most frequent negative monograms
head(arrange(monograms, monogram_senti, desc(frequency)), n = 10)## feature frequency rank docfreq group monogram_senti
## 27 ruins 214 27 191 all -1
## 51 ruin 128 50 114 all -1
## 73 steep 89 73 83 all -1
## 163 cave 45 161 44 all -1
## 172 ruined 42 172 39 all -1
## 294 dungeon 26 293 26 all -1
## 303 cold 26 293 22 all -1
## 327 cheap 24 316 24 all -1
## 353 unfortunately 22 346 21 all -1
## 453 miss 18 438 17 all -1I did a cursory look around the most frequently occurring positive and negative monograms and spotted some terms that appear to be inappropriately coded as negative for this context. The positive terms appear to be appropriately coded.
I determined that these terms were inappropriately coded by scanning through reviews that contained these terms and seeing how they were used. Some of the terms used to describe the castle are picked up as negative in the lexicon used but were instead used as neutral terms in the reviews. Here’s a table of terms that should have their sentiments re-coded:
| Terms | Current Sentiment | Context in Reviews | New Sentiment |
|---|---|---|---|
| ‘ruin’, ‘ruins’, ‘ruined’ | -1 | To describe the castle ruins within the attraction | 0 |
| ‘cave’, ‘caves’ | -1 | To describe the caves within the attraction | 0 |
| ‘dungeon’, ‘dungeons’ | -1 | To describe the dungeons within the attraction | 0 |
| ‘prison’, ‘prisons’, ‘jail’ | -1 | To describe the prison cells in the dungeon | 0 |
| ‘rail’, ‘rails’ | -1 | To describe the rails within the attraction | 0 |
| ‘siege’ | -1 | To describe the siege that occurred on the castle | 0 |
| ‘blind’ | -1 | To describe the Blind Jack statue in the attraction | 0 |
| ‘cheap’ | -1 | To discuss affordability of tickets | +1 |
| ‘disabled’ | -1 | To discuss disabled access within the attraction | 0 |
| ‘concession’ | -1 | To discuss concession tickets | 0 |
I’ve just done a cursory look over the most frequently occurring positive and negative monograms to identify these anomalies. There are likely other inappropriately coded terms that I did not pick up on that appear too infrequently to justify the resources needed to look for them.
Infrequent terms don’t appear often enough in reviews to make a huge impact on the final sentiment analysis even if they are inappropriately coded. Additionally, when creating word clouds to visualise the most frequent positive and negative terms, the infrequent terms will automatically be filtered away and would not affect the visualisation. So there’s limited yield in recoding them.
A more refined way of recoding the sentiments would be to determine the proportion of cases when the terms were used in a negative vs. neutral vs. positive context and recode sentiment values accordingly, but similar to my explanation above: the yield doesn’t justify the resources in my opinion.
Creating Word Clouds
Let’s recode the sentiments for the terms we’ve identified above. As the get_sentiment() function already has pre-set methods, I’m not able to find a way to edit the lexicon itself. Instead, I’ll recode the sentiments generated from the function for both monograms and bigrams. This involves quite a bit of manual work so please let me know if there’s a more efficient way about this.
#Creating a vector of inappropriately coded terms
neutrals <- c("ruin", "ruins", "ruined", "cave", "caves", "dungeon", "dungeons", "prison", "rail", "rails", "siege", "blind", "disabled", "concession")
positives <- c("cheap")
#Recoding sentiments for monograms
monograms_recoded <- monograms %>%
mutate(monogram_senti = case_when(
feature %in% neutrals ~ 0, #checks each row to see if the term in `feature` is within the `neutrals` vector
feature %in% positives ~ 1, #checks each row for "cheap"
TRUE ~ as.numeric(monogram_senti) #otherwise, retain original value
))
#Recoding sentiments for bigrams
bigrams_recoded <- bigrams %>%
mutate(bigram_senti = case_when(
grepl("railway", bigrams$feature) ~ as.numeric(bigram_senti),
rowSums(sapply(neutrals, grepl, bigrams$feature))>0 ~ as.numeric(bigram_senti)+1, #checking each row to see if any of the terms appear in the `feature` column, +1 to counteract the -1 from these terms
rowSums(sapply(positives, grepl, bigrams$feature))>0 ~ as.numeric(bigram_senti)+2, #+2 to go from -1 to +1
TRUE ~ as.numeric(bigram_senti)
))I can now create a word cloud for the most frequently used positive terms across all reviews and export them as .html and .png files.
#Creating a data frame of positive terms that appear at least 20 times
pos_mono <- monograms_recoded %>% filter(monogram_senti > 0, frequency > 20) %>% select(feature, frequency)
#Plotting word cloud for positive monograms
posmono_cloud <- wordcloud2(pos_mono, rotateRatio = 0, backgroundColor = "#fffde8", shuffle = T)
posmono_cloud#Exporting word cloud
saveWidget(posmono_cloud, "posmono.html", selfcontained = F) #as a .html file
webshot("posmono.html", "posmono.png", delay = 10) #as a .png file#Repeating the process for positive bigrams
pos_bi <- bigrams_recoded %>% filter(bigram_senti > 0, frequency > 20) %>% select(feature, frequency)
posbi_cloud <- wordcloud2(pos_bi, rotateRatio = 0, backgroundColor = "#fffde8", shuffle = T)
posbi_cloudYou can hover over the words to look at their respective frequencies. Now, I’ll repeat the process to obtain the word clouds for negative monograms and bigrams.
#Negative monograms word cloud
neg_mono <- monograms_recoded %>% filter(monogram_senti < 0, frequency > 4) %>% select(feature, frequency)
negmono_cloud <- wordcloud2(neg_mono, rotateRatio = 0, backgroundColor = "#f5dce2", shuffle = T)
negmono_cloud#Negative bigrams word cloud
neg_bi <- bigrams_recoded %>% filter(bigram_senti < 0, frequency > 4) %>% select(feature, frequency)
negbi_cloud <- wordcloud2(neg_bi, rotateRatio = 0, backgroundColor = "#f5dce2", shuffle = T)
negbi_cloudConducting Sentiment Analysis
I’ll be using the sentimentr package to determine polarity sentiments. The advantage that this package has over a bag-of-words method is that it calculates polarity at the sentence level and takes into account words that either negate or amplify (e.g. but, extremely).
With this package, the number of words in a sentence, even if neutral, matters to the calculation of polarity and so does punctuation, which is needed to distinguish between sentences. So I won’t use the cleaned text data we have and instead I’ll only remove numbers from the reviews before running the data through the sentiment analysis function. The function also automatically removes punctuation with the exception of pause punctuations.
#removing digits
knares_senti_clean <- gsub(pattern="\\d", replace=" ", knaresreview)As I had done, I will also recode the sentiments for the terms we’ve identified to be inappropriately coded. Thankfully, the sentimentr package allows me to directly edit the dictionary before running the analysis.
#Storing bing lexicon
bing <- get_sentiments("bing")
bing <- bing %>% mutate(sentiment = recode(sentiment, negative = -1, positive = 1))
#recoding lexicon
bing_recoded <- bing %>%
mutate(sentiment = case_when(
word %in% neutrals ~ 0,
word %in% positives ~ 1,
TRUE ~ sentiment))
#Converting it into a recognisable format for `sentimentr`
bing_key <- as_key(bing_recoded)Before I proceed further, let’s make sure that the dictionary and function operate well.
sentiment_by("I am a student.", polarity_dt = bing_key)## element_id word_count sd ave_sentiment
## 1: 1 4 NA 0sentiment_by("It's not the best.", polarity_dt = bing_key)## element_id word_count sd ave_sentiment
## 1: 1 4 NA -0.5This is just a quick test to check whether the function is working. I’m happy with the results - it was able to correctly detect that the first sentence is neutral, and the second is negative. Let’s now run this with the TripAdvisor reviews.
knares_sentiment <- sentiment_by(knares_senti_clean, polarity_dt = bing_key)
head(knares_sentiment)## element_id word_count sd ave_sentiment
## 1: 1 102 0.35905338 0.29048536
## 2: 2 33 0.23465585 0.48139741
## 3: 3 27 0.66700017 0.59129801
## 4: 4 40 0.41400633 0.03104775
## 5: 5 28 0.01226849 0.56867513
## 6: 6 122 0.37953690 0.39047863Just as a quick check of accuracy, I’ll take a look at the most negative, most positive, and neutral reviews. To do this, I’ll merge the knares_sentiment data frame with the reviews we have.
#since `knares_sentiment` is arranged in the same order as the original reviews, I'll just use cbind.
knares_complete <- cbind(knaresreview, knares_sentiment)
#Most positive reviews
posreviews <- arrange(knares_complete, desc(ave_sentiment)) %>% select(1, 5)
pandoc.table(head(posreviews, n = 3), split.tables = Inf)##
## ------------------------------------------------
## knaresreview ave_sentiment
## -------------------------------- ---------------
## worth a visit . excellent 1.641
## location good fixer upper
## opportunity, But really worth
## the visit with stunning views
## and easily accessable
##
## love this place . i adore 1.383
## knaresborough gorgeous
## placelovely river setting and
## castle , mother shipleys cave
## very eerie and worth a visit
## but on a nice day a river boat
## or picnic is just as lovely my
## fav place.
##
## Super . History really 1.344
## interesting and worth a visit,
## super views as well.
## ------------------------------------------------#Neutral reviews
neutreviews <- knares_complete %>% filter(ave_sentiment == 0) %>% select(1, 5)
pandoc.table(head(neutreviews, n = 3), split.tables = Inf)##
## ------------------------------------------------
## knaresreview ave_sentiment
## -------------------------------- ---------------
## Not much remains but views . 0
## The Castle is largely gone
## with only the keep and a few
## outer walls remainingFree to
## walk around and lookGreat
## place to get views of the
## river old town and rail bridge
##
## Visited yesterday after the 0
## Christmas market . We walked
## back to the car park via the
## castle, great views of the
## river and surrounding area,
## seen the ravens, a steep walk
## down to the river with steps.
##
## Walk around the grounds . We 0
## had a walk around the grounds
## we didn't go it as it was
## £3.40 for adults and not much
## cheqper for children and there
## wasn't much to see.
## ------------------------------------------------#Most negative reviews
negreviews <- arrange(knares_complete, ave_sentiment) %>% select(1, 5)
pandoc.table(head(negreviews, n = 3), split.tables = Inf)##
## ------------------------------------------------
## knaresreview ave_sentiment
## -------------------------------- ---------------
## Lovely old ruin with views of -0.4336
## the river below . We visited
## yesterday I must admit the
## weather was very poor cold and
## misty the castle ruins looked
## quite mysterious and sinister
## the views we’d hoped for where
## somewhat poor we will
## definitely come back another
## day
##
## Dog toilet . First time -0.3735
## visiting Knaresborough today
## and stumbled across the
## Castle. I have to say the view
## was lovely but having to wade
## through the piles of dog mess
## on the lawns was very very off
## putting.This was despite the
## signs saying that it was a
## poop a scoop area and bins
## being provided. DISGUSTING!
##
## freezing . what a lovely spot -0.3612
## but not great on a cold day
## like today.
## ------------------------------------------------Though there are some reviews where the calculated sentiments aren’t exactly the most accurate (for instance, I’d likely rate the most negative review as a neutral review), I’d say it generally has the polarity for most reviews right especially considering the speed of the analysis.
Now, I’ll run some summary statistics and plot out a distribution of the sentiments.
summary(knares_complete$ave_sentiment)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## -0.4336 0.2880 0.4058 0.4159 0.5399 1.6408sd(knares_complete$ave_sentiment)## [1] 0.2172107#Plotting distribution of sentiments
knares.plot <- ggplot(data = knares_complete, aes(x = ave_sentiment)) +
geom_density(fill = '#7CDF7C',alpha = 0.6) +
theme_bw()+
xlab('Sentiment')+
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank())+
geom_vline(xintercept = 0, color = "#E74C3C", linewidth = 1)#exporting the plot
ggsave("knaresbing.png", plot = knares.plot, scale = 1.5)Discussion of Results
knares.plot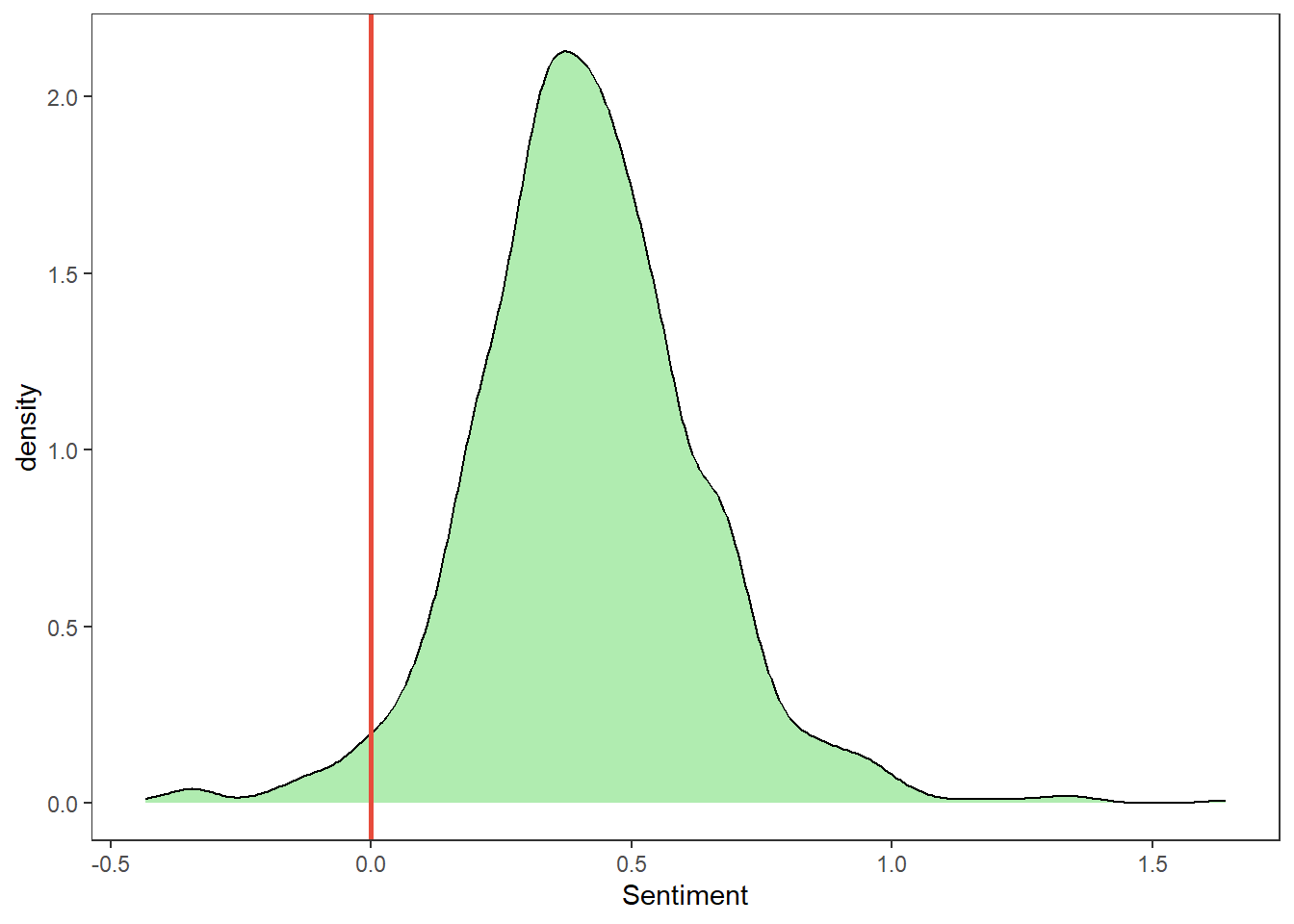
Figure 1: Distribution of sentiments
Based on the sentiment analysis conducted, it seems that perceptions towards Knaresborough Castle are overwhelmingly positive. Sentiments are also quite clustered, about 70% of reviews have a relatively positive sentiment of 0.2-0.6.
From the plot we also see that perceptions aren’t very polarised, neither do we have a lot of people disliking the attraction nor do we have a lot who are absolutely in love with it. This is rather surprising considering we generally expect more polarised views on review sites (though this could also be due to the choice of analysis method).

Figure 2: Most frequent positive monograms and bigrams

Figure 3: Most frequent negative monograms and bigrams
The word cloud of negative terms hints that the steep climb to the castle and the cold weather are two major pain points for visitors.
There are a few recommendations we can make based on this:
- Highlight the picturesque views of the castle in promotional materials and future marketing campaigns
- Further explore whether steepness and coldness are affecting the visitor experience and if so,
- Consider arranging alternative transportation arrangements to get to or around the castle
- Provide rest stops such as cafes where visitors can warm up
While this is a sample of an analysis conducted for one attraction, when evaluated in conjunction with the analyses for other attractions, we can get a gauge of the overall visitor experience and their perceptions towards attractions in Harrogate.
Limitations
However, there are a few limitations to the analysis conducted:
- This analysis is exploratory in nature and used to uncover potential directions to explore further (e.g. determining if steepness truly is an issue) but shouldn’t be used to draw firm conclusions.
- TripAdvisor reviews only account for a subset of visitors and potential visitors. It can’t directly tell us about the perception of Harrogate as a whole. Other methods (like mail-in questionnaires) should be pursued to directly address that.
- With more time and resources, we could explore more accurate methods of sentiment analysis beyond a simple bag-of-words approach.